
Danadata 002 - Desmitificando las capas de datos: No, GTM no tiene la exclusiva
Desmitificando la capa de datos: más allá de GTM y por qué esencial para tu estrategia digital


Una capa de datos única para gobernarlos a todos
Como siempre digo, nosotros, los data collection engineers, somos los amos y señores de las capas de datos. Somos quienes construimos, mantenemos, integramos y optimizamos esta estructura crucial. Y créeme, no es una tarea fácil.
En este artículo, me gustaría explicar exactamente para qué sirven las capas de datos y desmitificar las principales creencias que existen sobre ellas.
¿Qué es una capa de datos?
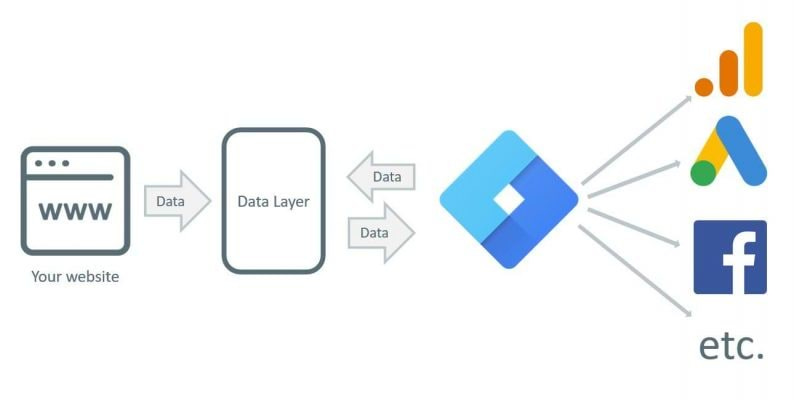
Empecemos por lo primero. Una capa de datos es básicamente un contenedor donde almacenamos y organizamos toda la información relevante sobre un activo digital (sitio web, aplicación) para poder enviarla a cualquier herramienta que la necesite. Desde los detalles de productos en una tienda online hasta interacciones de usuarios, la capa de datos facilita la recolección y transmisión de información de manera estructurada. Así, no solo es esencial para el análisis, sino también para tomar decisiones estratégicas informadas.

Pero si lo que quieres es tirarte el rollo y que los más técnicos se sorprendan, diles: “La capa de datos es una capa de abstracción intermedia entre la capa de la aplicación (donde interactúan los proveedores, APIs, o lógica del backend) y la capa de experiencia (la aplicación o sitio web donde el usuario interactúa, es decir, el frontend)”.
Un poco de historia
La idea de una capa de datos no es nueva, pero ha evolucionado enormemente. En 2013, el W3C introdujo el Customer Experience Digital Data Layer (CEDDL), un primer intento de estandarizar cómo organizamos y transmitimos datos —muy resumido, se trataba de una capa de datos con un claro enfoque estático, donde había que montar auténticos quilombos para añadir cualquier interacción de usuario—. Luego, Google revolucionó el concepto al incorporar el método push() en su Event-Driven Data Layer (EDDL), permitiendo que la capa de datos respondiera dinámicamente a eventos de usuario. Este enfoque cambió el juego, y otras herramientas, como Adobe, rápidamente siguieron su ejemplo.

Desmitificando creencias populares (y erróneas) sobre las capas de datos
A continuación, vamos a desmentir algunos de los mitos más extendidos sobre las capas de datos y a explicar cómo pueden ser increíblemente útiles sin necesidad de GTM —sí, lo has leído bien— o cualquier gestor de etiquetas.
Mito 1: “La capa de datos es exclusiva de Google Tag Manager”
Realidad: Aunque Google popularizó el concepto con su dataLayer, cualquier herramienta de marketing que trabaje con datos necesita una capa de datos. Desde plataformas de publicidad hasta CRM y sistemas de personalización, muchas tecnologías usan su propia versión de capa de datos para enviar o recibir información, pero esta suele ser efímera y desaparecer con cada interacción.
Ejemplo de transacción de Facebook:
fbq('track', 'Purchase',
// begin parameter object data
{
value: 115.00,
currency: 'USD',
contents: [
{
id: '301',
quantity: 1
},
{
id: '401',
quantity: 2
}],
content_type: 'product'
}
// end parameter object data
);Ejemplo para enviar evento en Mixpanel:
// Send a "Played song" event to Mixpanel
mixpanel.track("Played song",{
"genre": "hip-hop" // with an event property "genre" set to "hip-hop"
}
);Como puedes comprobar, ambas herramientas, por separado, necesitan que les pases diferentes variables… ¿Por qué no agruparlas todas en una fuente cómun?
¡No, GTM no tiene la exclusiva!
Mito 2: “Solo sirve para los tag managers”
Realidad: La capa de datos es increíblemente útil para muchas aplicaciones más allá de los tag managers. Te permite mantener un “repositorio de datos” estandarizado y accesible, lo que mejora la consistencia y eficiencia de cualquier implementación analítica o de marketing. Gracias a una capa de datos bien diseñada, puedes reducir la dependencia de ETLs al volcar los datos en bruto en data warehouses, facilitar la integración con plataformas como CRMs y hasta optimizar estrategias de personalización.
Si te mola el término Gobernancia del dato y todavía no tienes una capa de datos agnóstica… ¿a qué estás esperando?
Mito 3: “No tiene sentido utilizarlo sin GTM”
Realidad: Implementar una capa de datos estandarizada tiene beneficios tangibles, con o sin gestor de etiquetas. Al estructurar tus datos de manera eficiente, semántica y consistente, mejoras la calidad del análisis y facilitas la interoperabilidad con distintos proveedores. Además, al ser independiente, garantiza que no estés atado a una sola herramienta. Incluso si gestionas tus herramientas de análitica directamente desde código.
En otras palabras, la capa de datos es tu amiga fiel, te cases con GTM o no.
Mito 4: “Una capa de datos es solo una lista de variables”
Realidad: Esto es como decir que una novela es solo una lista de palabras. La capa de datos es una estructura que sigue un concepto clave-valor y que se enriquece con elementos dinámicos y estáticos. No es solo una lista de variables; es un “ser vivo” que evoluciona junto a las necesidades de negocio, capturando el estado de la aplicación en tiempo real y facilitando análisis de alto nivel.
Si lo que quieres es mantener este “ser vivo”, mi recomendación es que te valgas de un SDR y documentes absolutamente todo.
Mito 5: “No tiene sentido porque al final la capa de datos está en GTM; si no está, la creo del DOM y listo”
Realidad: Sí, es cierto que puedes crear variables desde el DOM sin una capa de datos. Pero hacerlo es como construir una casa sin cimientos: puede funcionar al principio, pero no es nada robusto. Extraer datos directamente del DOM afecta el rendimiento de tu analítica, y, peor aún, te expones a race conditions. Estas condiciones de carrera ocurren cuando intentas capturar datos que aún no están listos en el DOM, lo que puede generar inconsistencias y errores en los datos. Además, cuando creas las variables de capa de datos dentro de la herramienta de GTM —o Adobe Launch, por ejemplo—, lo que realmente estás haciendo es declarar la variable dentro de tu gestor de etiquetas capurando dicho valor de la capa de datos, ni más ni menos.
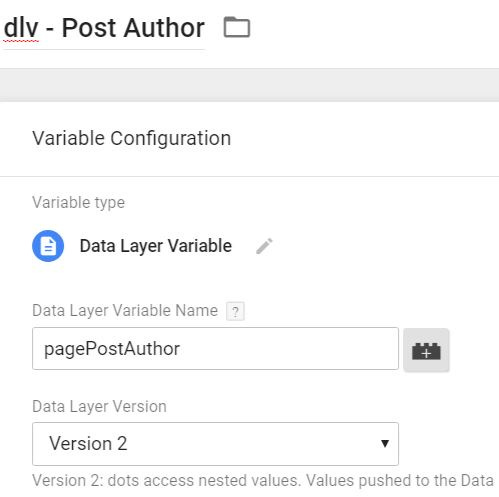
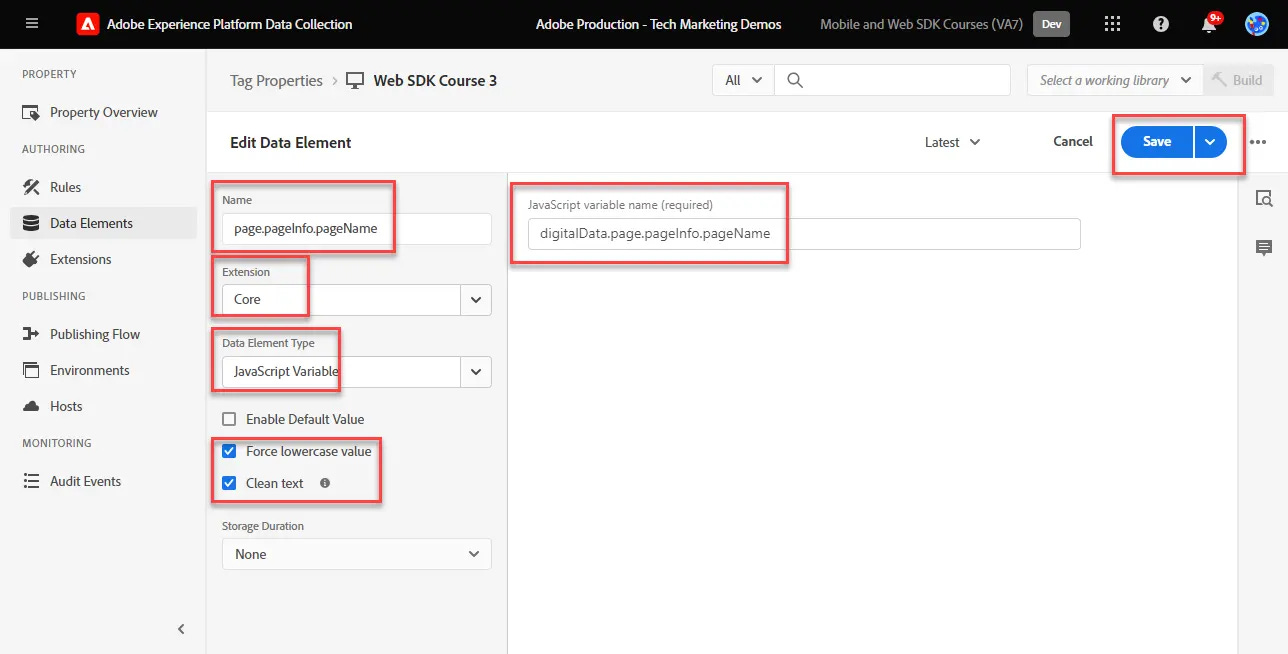
Una capa de datos estructurada y predefinida asegura que los datos estén siempre disponibles y consistentes en cada interacción, sin que tengas que esperar a que el DOM se termine de cargar o preocuparte por la sincronización.
“La capa de datos es una capa de abstracción intermedia entre la capa de la aplicación (donde interactúan los proveedores, APIs, o lógica del backend) y la capa de experiencia (la aplicación o sitio web donde el usuario interactúa, es decir, el frontend)”.
Los beneficios clave de una capa de datos bien estructurada
Implementar una capa de datos va más allá de satisfacer la curiosidad de los frikis de datos (como nosotros). Aquí algunos de sus principales beneficios:
Automatización de eventos analíticos: Al definir eventos en la capa de datos, puedes automatizar la recolección de información de manera consistente y semántica, sin depender de código específico en cada página o componente.
Agrupación de contenido: Te permite estructurar y agrupar información, facilitando la identificación de cambios o inconsistencias en los datos.
Capacidades de e-commerce: En entornos de e-commerce, una capa de datos permite capturar variables de conversión de manera fiable y estandarizada, mejorando el seguimiento de ventas y ROI.
Audiencias y segmentación: Al organizar datos sobre la procedencia de los usuarios, se facilita la creación de audiencias y se optimizan las estrategias de marketing.
Estructura Recomendada para una Capa de Datos
Para que sea realmente útil, una capa de datos debe tener al menos cuatro o cinco objetos principales, cada uno alineado con una necesidad de negocio específica. Aquí tienes una estructura básica:
Content: Información estática sobre la página, como el tipo de contenido o la URL.
User: Datos sobre el usuario, tanto estáticos como dinámicos (ej., tipo de usuario o preferencias).
Campaign: Información de campañas, útil para rastrear de dónde vienen los usuarios.
Ecommerce: Variables relevantes de productos y transacciones.
Event: Información dinámica sobre las interacciones del usuario.
Nota: Mi recomendación es basar esta estructura por tipología de página. De esta forma, fácilmente podrás definir estos grupos y declarar qué variables quieres que vayan en cada uno de ellos. Y muy importante: “no todas las tipologías de página tienen que tener todos los grupos declarados”.
Y si me permites, mi consejo es que te valgas de las llamadas API y lógica del back-end para crear y alimentar tu capa de datos. Piensa que justo estas dos cosas son las principales que permiten que tu página muestre los datos e interactúes con ella, así que tiene todo el sentido del mundo que te centres en ellas para pintar tu capa de datos, ¿no crees?
No pongas todos tus datos en una sola “cesta” (o en un solo proveedor)

Una capa de datos bien estructurada es el alma de cualquier implementación de datos. No solo facilita la recolección y transmisión de información, sino que es una herramienta clave para mantener la consistencia, la escalabilidad y la resiliencia en tu ecosistema de datos. Así que, ya sea que uses GTM, Adobe, o cualquier otra herramienta, recuerda que la capa de datos es tu mejor aliada en la búsqueda de una analítica de calidad. ¡Y no dejes que te digan lo contrario!